
![]()
![]()
![]()
![]()
![]()
![]()
![]()

|
Интеллектуальные решающие машины (ИРМ) |
Научная деятельность |
|
|
|
|
Современное состояние развития
вычислительной техники в Украине |
|
|
Интеллектуальные решающие машины |
|
|
В Институте кибернетики НАН Украины, развивая идеи академика В.М.Глушкова, выполняются работы по созданию высокопроизводительных ЭВМ с параллельными кластерными и так названными знаниеориентированными архитектурами, с реализацией ЯВУ и СЯВУ и с глубокоавтоматизированной организацией вычислительного процесса. Эти работы базируются на идеях В.М.Глушкова, касающихся повышения уровня интеллектуализации современных ЭВМ. Речь идет о создании нового класса ЭВМ - интеллектуальных решающих машин (ИРМ) и организации параллельного программирования в мультипроцессорных интеллектуальных распределенных системах, построенных на базе ИРМ. Предложены основные концепции и разработана система программирования на ЯВУ "С+Граф", обеспечивающего эффективную работу со знаниями (как сложными структурами данных) и централизовано-децентрализованное управление в виртуальном распределенном вычислительном пространстве. Параллельная модель программирования в С+Граф зиждется на модели многопотокового монопроцессорного программирования базового языка Java, функционирующей в сети виртуальных С+Граф-машин. В целом, предложенную в докладе идеологию можно считать эффективным развитием глушковского принципа структурной интерпретации ЯВУ в применении к знаниеориентированным мультимикропроцессорным системам. Рассмотрена структура оборудования и характеристики базового варианта ИРМ. Современное состояние развития вычислительной техники в Украине Современный этап развития информатики характеризуется мощным прорывом новых информационных технологий практически во все сферы человеческой деятельности. В основу создания современных информационно-аналитических систем для эффективного управления экономикой развитых стран, обеспечения их обороноспособности, охраны окружающей среды и т.п. внедряются методы системного анализа, оптимизации, повышения уровня машинного интеллекта. Большая и сверхбольшая вычислительная размерность этих задач, огромные информационные массивы и скорости их обработки, высокая пропускная способность каналов связи являются таковыми, что решение указанных задач без использования современных высокопроизводительных ЭВМ становится неосуществимой проблемой. На сегодняшний день в Украине такие ЭВМ практически
отсутствуют и их место никак не могут занять мощные персональные
ЭВМ, которых в последние годы приобретено в нашей стране уже немало.
Отставание Украины от мирового уровня в оснащенности высокопроизводительными
вычислительными системами органов государственной власти, институтов
Национальной Академии Наук Украины (НАНУ), университетов, отраслевых
НИИ и КБ достигло критического уровня, и если срочно не принять
необходимых мер, то в ближайшем будущем это может привести к угрожающей
ситуации в стране в целом, не говоря уже о потере ведущих позиций
в науке, создании наукоемкой продукции, технологиях проектирования
сложных объектов и процессов и т.п. Естественно, Украина не может конкурировать с США, Японией и развитыми странами Западной Европы по всем направлениям разработки компьютерной техники, в частности, с технологическими достижениями США и Японии в области микроэлектроники, без миллиардных капиталовложений. И тем не менее, Украина может и должна найти собственную нишу в области разработок средств вычислительной техники (СВТ), которые будут защищать ее национальные интересы и будут обеспечивать интеллектуальный потенциал как передового цивилизованного государства, тем более что на протяжении многих десятилетий Украина весьма успешно работала над собственными проектами в области высокопроизводительных СВТ. И сегодня эти работы продолжаются, правда, не таким
широким фронтом, но довольно интенсивно. В частности, речь идет
о создании ряда высокопроизводительных ЭВМ с новыми архитектурными
и структурными принципами построения. Это направление наших исследований
является оригинальным, и в последние годы финансировалось в рамках
международных научных программ CRDF, УНТЦ, INTAS и др., а также
за средства бюджета НАН Украины. Известно, что производительность и интеллектуальность - важнейшие факторы, определяющие развитие современных универсальных ЭВМ. Первый фактор привел к созданию параллельных архитектур ЭВМ, наиболее рациональным базисом которых являются универсальные микропроцессоры. В таких мультимикропроцессорных системах вычислительный процесс организуется на основе распределенной обработки информации, в которой микропроцессоры одновременно выполняют определенные целостные задания - независимые ветви пользовательских программ. Второй фактор приобретает конкретность при использовании введенного в начале 70-х г.г. прошлого века Виктором Михайловичем Глушковым и проф. З.Л. Рабиновичем понятия машинного интеллекта [1], которым определено и структурировано обиходное выражение "внутренний интеллект ЭВМ". Тогда интеллектуализация ЭВМ рассматривается как повышение уровня их машинного интеллекта. В ИК НАНУ на протяжении последних 5-6 лет ведутся исследования по созданию нового ряда ЭВМ с широким диапазоном конфигураций - от мощных рабочих станций до супер ЭВМ, - характеризуемого высокой и сверхвысокой производительностью и высоким уровнем машинного интеллекта (МИ). Тенденции создания подобного класса ЭВМ в мире только просматривается в литературе и отдельных выступлениях на конференциях. Таким образом, сегодня имеется определенная ниша в мировом вычислительном машиностроении - высокопроизводительные интеллектуальные ЭВМ - и это направление исследований является весьма перспективным. Естественно, что создание универсальных высокопроизводительных интеллектуальных ЭВМ, отвечающих современным требованиям, является очень сложной задачей. К таким ЭВМ нужно двигаться поэтапно, создавая на каждом этапе модель ЭВМ с более высокими характеристиками, чем на предыдущем. При этом ЭВМ, полученные на данном этапе, должны закрывать свои конкретные сферы применения. Это очень важно для обеспечения гармонизации процесса информатизации страны, который основан на ЭВМ с различными характеристиками по производительности, оснащению, стоимости и т.д. В такого рода подходе к созданию высокопроизводительных ЭВМ отражен главный методологический принцип В.М.Глушкова - единство ближних и дальних целей: в процессе достижения дальних целей необходимо получать и использовать промежуточные результаты, которые служат достижению ближних целей. В рамках данного глобального направления в ИК НАНУ проводятся исследования по разработке распределенных параллельных знаниеориентированных архитектур, названных интеллектуальными решающими машинами, реализующими языки высокого и сверхвысокого уровней и эффективную работу с базами данных и знаний большого объема при решении как традиционно-вычислительных задач, так и задач искусственного интеллекта [2-8]. Это направление исследований естественным образом
вытекает из тех основательных заделов, которые в свое время были
сделаны в ИК НАНУ: Основные принципы построения ИРМ Архитектура ИРМ интегрирует в себе четыре главных свойства: Базовый входной язык в машине класса ИРМ, С+Граф, наследует свойства языка Java и расширен библиотечными средствами выполнения параллельных операций над графами, массивами и средствами централизовано-децентрализованного управления вычислительным процессом. Внутренний язык в машине ИРМ - это Java-подобный язык высокого уровня, с помощью которого решается одна из главных языковых проблем: существенного сокращения семантического разрыва между исходными пользовательскими ЯВУ-программами и внутренним их представлением в машине, возможность работы со знаниями как со сложными структурами данных (ССД), отсутствие необходимости участия пользователя в организации вычислительного процесса. Идея подобного использования внутреннего ЯВУ берет свое начало со времен создания ЭВМ МИР, Украина, КИТ [9, 10], в которых была реализована идея структурной интерпретации ЯВУ с целью более эффективной их реализации. Сейчас эта идея сохраняется, но добавилось еще одно важное обстоятельство, связанное с наличием различных современных аппаратно-программных платформ - Intel, HP, Sun, Dec и др. - каждой со своими системами команд, используемых в них микропроцессоров (МП) и операционных систем (ОС). Для каждой такой платформы, как правило, разрабатывается набор своих компиляторов с различных ЯВУ на систему команд того или иного МП этой платформы. Но при этом теряется переносимость исполняемых программ с одной платформы на другую. Для того чтобы сделать исполнимые коды разных платформ переносимыми, вводится промежуточный уровень команд - внутренний язык высокого уровня в виде виртуальной машины - и делается один компилятор с данного внутреннего языка для всех платформ. На язык С+Граф достаточно просто компилируются или конвертируются программы с ряда общепринятых языков высокого и сверхвысокого уровней типа С++, Java, Paskal, Fortran, Bаysic, Prolog и др. Уже только поэтому на машинах класса ИРМ естественно реализуются традиционные программы для вычислительных задач. Знания и сложные структуры данных (ССД) представляются в ИРМ в виде ориентированных графов огромной сложности, вершины и дуги которых помечены. Для каждого графа существует распределенное представление в виде связного списка (матрицы смежности и т.п.), кроме того, граф может быть представлен как обобщенный объект (без внутреннего строения). Совокупность графов-объектов может представлять собой семантическую сеть, с которой можно работать, не прибегая к распределенному представлению. Графы играют одну из основополагающих ролей. С одной стороны граф - это сложная структура данных, т.е. тип данных, характеризуемый своими объектами и операциями над ними, с другой стороны - это может быть исполняемая программа, т.е. тип управления. С помощью графов достаточно просто представляются сложные динамические структуры данных и знаний типа деревьев (в том числе бинарных), семантических сетей, которые могут динамически изменяться во времени и при этом расти вниз, вширь и т.п. Для обработки графовых структур в язык С+Граф введены
объектно-ориентированные средства: класс типа граф и его методы
- совокупность операций и механизмов взаимодействия при работе с
переменными типа "граф". В качестве примера таких функций
можно привести функции построения и уничтожения графа, поиска по
графу, вставки подграфов в граф, формирования новой вершины, дуги
и т.п. Язык С+Граф содержит ряд теоретико-множественных операций
над графами, алгебраических операций над графами как конечными автоматами,
операций с отношениями на дугах графов, операций управления с помощью
фишек и т.п. Доступ к графам и его компонентам осуществляется по
именованным адресам или ассоциативно, по имени или образцу. Виртуальная С+Граф-машина (процессор) является абстрактной машиной. Она предназначена для исполнения байт-кодов, сгенерированных компилятором, который транслирует исходные тексты С+Граф-программ в коды виртуальной С+Граф-машины (ВМ). Эта машина является виртуальной в том смысле, что она не существует в виде реальных микросхем и других устройств, а представляет собой программный эмулятор, реализованный на какой-либо традиционной аппаратной платформе. Различаются два типа процессоров: обрабатывающий и управляющий. Управляющий процессор (УП) является предопределенным и главным для данной вычислительной сети и связан с каждым виртуальным обрабатывающим процессором как по управлению, так и по передаваемым данным. УП задает распределенное управление в виртуальной вычислительной сети. Язык С+Граф активно использует библиотеку классов (библиотеку
объектно-ориентированного программирования) и компилятор Java. Все
основные расширения осуществляются средствами этого языка. Расширенная библиотека классов позволяет решать широкий класс задач, не заботясь о деталях организации вычислительного процесса. Предварительное распараллеливание и распределение ССД и ветвей программ по виртуальному вычислительному пространству осуществляются методами расширенной библиотеки совместно со средствами входного языка высокого уровня С+Граф и стандартной мультипроцессорной ОС, с которой эта библиотека совместима. Централизованное и децентрализованное управление в ИРМ. Функции автоматического программирования выполняет компилятор и интерпретатор - виртуальная машина - входного языка С+Граф. Компилятор компилирует двоичные коды команд, а интерпретатор исполняет их средствами языка низкого уровня - командами МП. Для поддержания многопроцессорного выполнения с каждым физическим МП связывается одна или более виртуальных С+Граф машин. Поэтому приходится строить двухуровневый внутренний язык с реализацией каждого уровня на соответствующих компонентах - программных и аппаратных. Верхний уровень - это внутримашинное представление входного алгоритмического языка С+Граф после компиляции. Откомпилированная программа, которую должна выполнять виртуальная машина, сохраняется в двоичном файле, который имеет независимый от аппаратно-программной платформы формат - так называемый Class-файл. Этот уровень фиксирует назначение машины (например, Java-машины) в целом и соответствующее ему централизованное управление с помощью УП. Нижний уровень - обычный язык команд микропроцессора. Этот уровень фиксирует непосредственную обработку информации в поле МП и соответствующее этому уровню децентрализованное управление, т.е. интерпретацию команд в языке С+Граф командами МП и исполнение этих команд. Предусматривается, что интерпретатор внутреннего языка может обрабатывать одновременно множество параллельных ветвей или отдельных независимых задач. Этому множеству может быть поставлено в соответствие некоторое поле обрабатывающих ВМ (разбитых на кластеры), а они, в свою очередь отображаются на поле физических процессоров. Поскольку одновременно работающих ВМ (процессоров) может быть много, то это и обеспечивает возможность параллельной интерпретации внутреннего языка С+Граф. Когда множество ВМ превышает множество физических МП, то у последних образуются очереди на исполнение различных частей программы. Интерпретатор отслеживает исполнение всех параллельных
ветвей и осуществляет обращение за системными средствами к ОС для
оптимальной загрузки поля МП и реализации последовательно-параллельной
обработки в этом поле. Таким образом, интерпретатор внутреннего
языка дополняет ОС на этапе обработки ССД и исходных программ. В
то же время он инициирует обращения к ОС для вызова ее стандартных
функций для распределения ветвей задач между ВМ, включая постановку
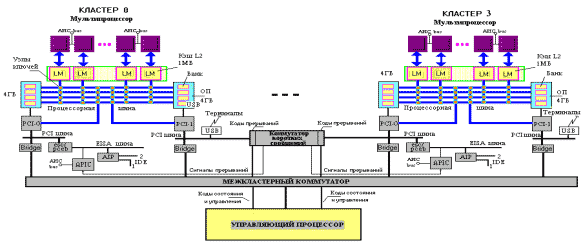
их в очередь, распределение памяти и др. Таким образом, в ИРМ реализуется двухступенчатая интерпретация. Одна - на уровне интерпретатора внутреннего языка С+Граф, другая - на уровне виртуальных микропроцессоров, размещенных в памяти исполнительных (физических) МП. Отсюда у нас и появилось понятие двухступенчатой интерпретации при управлении параллельной архитектурой с двухуровневым внутренним языком. Именно это обстоятельство позволяет реализовать ЯВУ на параллельной архитектуре. Оборудование ИРМ строилось таким образом, чтобы аппаратно поддержать внутренний язык, механизмы работы с графами, эффективно осуществлять централизованное и децентрализованное управление. В оборудовании ИРМ, так же, как и в других высокопроизводительных системах, используется кластерный принцип компоновки системы, но со специально выделенным (или совмещенным) одним управляющим процессором и средствами коммутации между кластерами (см. рис. 1). Кластерные архитектуры сегодня являются одними из перспективных в мире, число их постоянно растет, объем средств на создание таких архитектур постоянно увеличивается. Если в 1998 году это были сотни миллионов долларов, то сегодня это уже миллиарды долларов.
Блок-схема функциональной архитектуры ИРМ Кластер - это симметричная параллельная архитектура типа SMP, в которую для улучшения трафика вводится несколько шин. Совокупность кластеров имеет черты как МРР - архитектур, так и SPP-архитектур [5]. В состав каждого кластера может входить от 4 до 8 микропроцессорных модулей, построенных на МП различного типа (RISC, SISC, цифровых сигнальных процессорах и др.). Кластеры связываются между собой двумя типами коммутаторов: коммутатором коротких сообщений (ККС) и магистральным коммутатором каналов (МКК). ККС - бесконфликтная схема, которая передает коды прерываний между МП кластеров для взаимной синхронизации их работы при децентрализованном управлении микропроцессорными модулями дулями. МКК - быстрая система коммутации со специальным механизмом арбитража без задержек. ККС осуществляет передачу байтовых сигналов прерываний между микропроцессорными модулями для инициирования нового процесса, либо прерывания старого, либо для инициирования передачи большого массива данных, которая выполняется уже через быстрый МКК. Управляющий процессор (УП) предназначен для централизованного управления и синхронизации работы микропроцессорных модулей. УП в своей кэш-памяти второго уровня содержит управляющие структуры - таблицы, стеки, очереди, сообщения, а также карты прохождения запросов пользователей и их программ. УП связывается шинами управления и состояния с каждым микропроцессорным модулем через буферные регистры, шину прерывания и шины данных кластеров. Для обмена данными большого объема УП связывается с памятью каждого кластера через межкластерный коммутатор каналов (МКК). Децентрализованное управление в пределах одного кластера осуществляется одним из МП, назначаемого УП в качестве ведущего. Получив от УП адрес входа в программу, ведущий МП самостоятельно распределяет ее исполнение среди других МП кластера. Каждый МП кластера исполняет свою заданную ветвь программы с возможным обращением за данными через ККС и МКК в другие кластеры и завершает свою работу выходом из этой программы и переходом в режим ожидания. Затем этот процесс повторяется, но уже при обработке другой ветви программы. При инициализации системы во все микропроцессоры загружается копия ядра интерпретатора внутреннего языка, часто используемые подпрограммы ОС, математические функции, библиотечные функции ЯВУ (например, функции распределения памяти, обработки очередей, сортировки и т.п.). Сегодня у нас разработано два опытных образца ИРМ. Первый из них - 2-х кластерный комплекс с 4-мя процессорами типа Pentium 2 и коммутаторами на ПЛИСах - 100тысячниках. Характеристики производительности этого образца не очень высоки. Однако на нем удалось проверить основные идеи, поработать с графовыми задачами из различных предметных областей и т.п. За последние несколько месяцев нам с нашим партнером - фирмой ЮСТАР (г. Киев) - удалось построить полноценный мощный 4-х кластерный 8-ми процессорный комплекс -КЛАСТЕР - ИК НАНУ - на современных МП Duron c тактовой частотой более 1 МГц и КЭШами 2-х уровней, большой оперативной и внешней памятью. Сейчас этот комплекс находится в интенсивной опытной эксплуатации. Стоимость созданного кластера составила менее 4-х тыс. долларов. При появлении дополнительных средств мы тут же учетверим мощность этого кластера вначале до 32-процессорного варианта, а затем - до 64-процессорного. Это будет, по-видимому, самая мощная вычислительная система в Украине, на базе которой уже в ближайший 1-1,5 года можно будет организовать первый отечественный суперкомпьютерный центр. На основании экспериментов с опытными образцами в настоящее
время нами предложен проект базового варианта машин класса ИРМ (см.
табл. 1-3). Все решения по этому проекту запатентованы 3 патентами
- одним российским - на архитектуру и структуру вычислительной системы
[15], и двумя украинскими - на вычислительную систему [16] и на
средства бесконфликтной коммутации [17]. Мы постоянно отслеживаем
появление новых электронных компонентов, языков параллельного программирования
и соответственно пересматриваем архитектуру и структуру ИРМ с тем,
чтобы соответствовать современному состоянию развития СВТ в мире. Табл.1. ХАРАКТЕРИСТИКИ ОБОРУДОВАНИЯ БАЗОВОГО ВАРИАНТА ИРМ КЛАСТЕРЫ С ОБРАБАТЫВАЮЩИМИ ПРОЦЕССОРАМИ Табл.2. ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ БАЗОВОГО ВАРИАНТА ИРМ С+Граф - оригинальный входной и внутренний ЯВУ, обладающий
эффективными механизмами параллельного программирования: наследует
свойства семейства языков С, С++, Javа и функционально развит в
направлении осуществления параллельной обработки как программ, так
и ориентированных графов, представляющих семантические сети. Конверторы
(компиляторы) с известных ЯВУ на язык С+Граф. Параллельный интерпретатор
с С+Граф на внутренний язык микропроцессоров. Стандартные ОС - Windows
NT, Linux. Стандартные языки - С, С++, Java, Pascal, Fortran и др.
Интегрированный интеллектуальный интерфейс - многооконная диалоговая
система. Табл.3. ПРОИЗВОДИТЕЛЬНОСТЬ БАЗОВОГО ВАРИАНТА ИРМ ПРОИЗВОДИТЕЛЬНОСТЬ ИЗ СПЕКТРА WINBENCH98 ДЛЯ КЛАСТЕРА
В РАСЧЕТЕ НА ОДИН ПРОЦЕССОР:Целочисленных операций в секунду - не
менее Dhrystones 3550 MIPS; Таким образом, нами представлены основные принципы построения ЭВМ класса ИРМ, рассмотрены методы пользовательского и автоматического (внутреннего) программирования для машин класса ИРМ. Для пользовательского параллельного программирования предложен входной язык С+Граф, основанный на базовых языках С++ и Java и включающий в себя дополнительные средства работы со сложными структурами данных (графами и др.). Внутренний язык С+Граф аналогичен входному и является средством представления виртуальной С+Граф-машины. Перевод в коды этой машины программ со входного языка С+Граф осуществляет компилятор. Виртуальная машина программно интерпретирует стандартизованный выходной код компилятора. Таким образом пользователь многопроцессорной системы с компонентами, работающими на языках низкого уровня, общается с ней исключительно на ЯВУ и, более того, полностью свободен от организации физического процесса вычислений. Такой подход можно считать эффективным развитием идей акад. В.М.Глушкова, в частности известного принципа структурной интерпретации ЯВУ, но уже в применении к многопроцессорным знаниеориентированным системам, и соответственно, называть его принципом структурно-программной распределенной интерпретации ЯВУ. Руководитель проекта: Коваль В.Н. Разработчики: Любарский В.Ф., Мушка В.И., Митрофанова А.Е., Хабинец Н.П. В.Н.Коваль, О.Н.Булавенко, З.Л.Рабинович 1. Рабинович З.Л. О концепции машинного интеллекта
и ее развитии // Кибернетика и системный анализ. - 1995. - № 2.
- С. 163 - 178. |
|